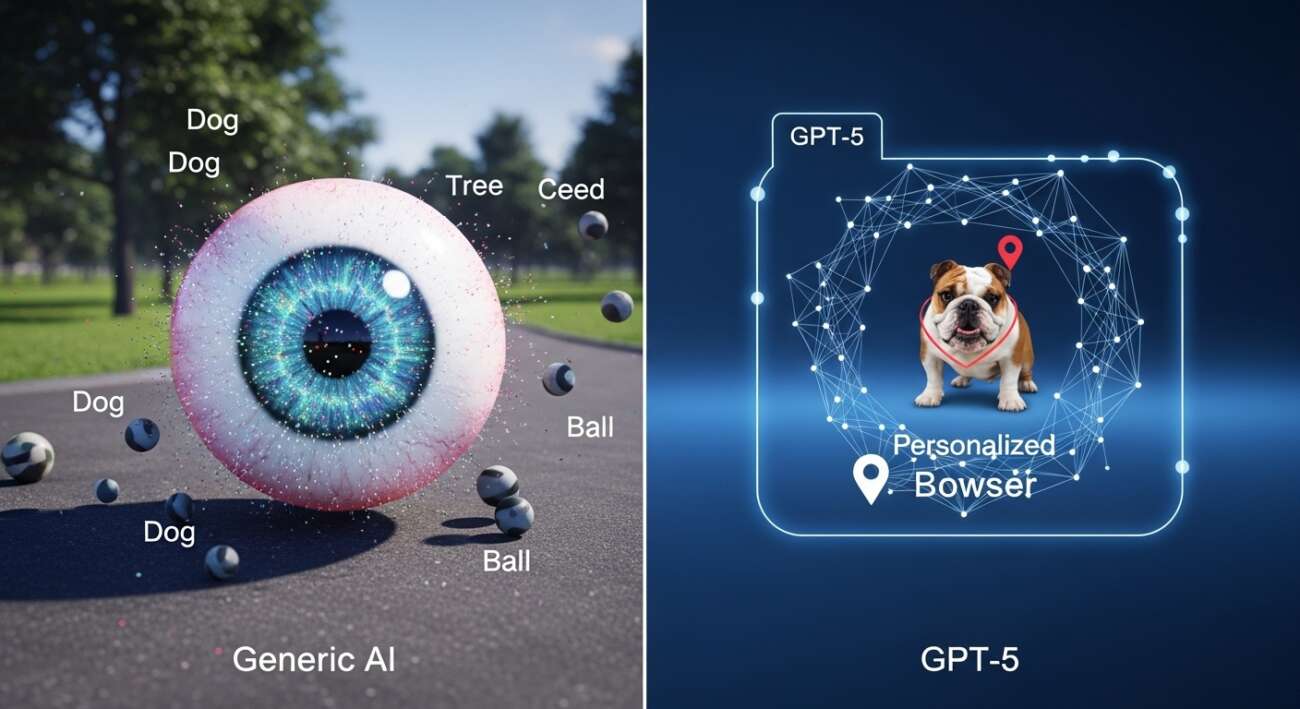
¿Te imaginas poder usar la IA para encontrar a tu perro en el parque mientras estás en el trabajo? Aunque los modelos de IA generativa, como GPT-5, son excelentes para reconocer objetos generales (por ejemplo, ‘un perro’), a menudo fallan al intentar localizar objetos personalizados, como ‘Bowser, el bulldog francés de Juan’. Pero no te preocupes, ¡la solución está aquí!
Nuevo método de entrenamiento para una IA más observadora
Investigadores del MIT y el MIT-IBM Watson AI Lab han creado un nuevo método de entrenamiento que enseña a los modelos de visión-lenguaje a localizar objetos personalizados en una escena. La clave está en utilizar datos de seguimiento de video cuidadosamente preparados, donde el mismo objeto se rastrea a través de múltiples fotogramas. Esto obliga al modelo a centrarse en las pistas contextuales para identificar el objeto, en lugar de depender de conocimientos previamente memorizados.
Imagina que le muestras al modelo algunas imágenes de tu mascota. Después de ser reentrenado con este método, el modelo será capaz de identificar la ubicación de tu mascota en nuevas imágenes con mayor precisión.
¿Cómo funciona este entrenamiento?
El método se basa en el ajuste fino (fine-tuning) de los modelos de visión-lenguaje (VLM). El problema con los datos de ajuste fino típicos es que provienen de fuentes aleatorias y muestran colecciones de objetos cotidianos sin coherencia entre las imágenes. Los investigadores del MIT solucionaron esto creando un nuevo conjunto de datos a partir de videoclips que muestran el mismo objeto moviéndose a través de una escena.
Pero eso no fue todo. Los investigadores se dieron cuenta de que los VLM tendían a “hacer trampa” y a identificar los objetos basándose en el conocimiento adquirido durante el preentrenamiento, en lugar de utilizar las pistas contextuales. Para evitar esto, utilizaron pseudo-nombres en lugar de los nombres reales de las categorías de objetos. Por ejemplo, cambiaron el nombre del tigre a “Charlie”.
“Nos tomó un tiempo descubrir cómo evitar que el modelo hiciera trampa. Pero cambiamos el juego para el modelo. El modelo no sabe que ‘Charlie’ puede ser un tigre, por lo que se ve obligado a mirar el contexto”, explica Jehanzeb Mirza, investigador postdoctoral del MIT y autor principal del artículo.
Implicaciones y Futuro
Este nuevo enfoque podría ayudar a los futuros sistemas de IA a rastrear objetos específicos a lo largo del tiempo, como la mochila de un niño, o a localizar objetos de interés, como una especie de animal en el monitoreo ecológico. También podría ayudar en el desarrollo de tecnologías de asistencia impulsadas por la IA que ayuden a los usuarios con discapacidad visual a encontrar ciertos elementos en una habitación.
“En última instancia, queremos que estos modelos puedan aprender del contexto, tal como lo hacen los humanos. Si un modelo puede hacer esto bien, en lugar de volver a entrenarlo para cada nueva tarea, podríamos simplemente proporcionar algunos ejemplos e inferiría cómo realizar la tarea a partir de ese contexto. Esta es una habilidad muy poderosa”, dice Mirza.
Los investigadores planean seguir estudiando por qué los VLM no heredan las capacidades de aprendizaje en contexto de sus LLM base y explorar mecanismos adicionales para mejorar el rendimiento de un VLM sin necesidad de volver a entrenarlo con nuevos datos.
En resumen
El nuevo método de entrenamiento del MIT mejora significativamente la capacidad de los modelos de IA para localizar objetos personalizados en imágenes y videos. Esto abre un mundo de posibilidades para aplicaciones prácticas en diversos campos, desde la asistencia a personas con discapacidad hasta el monitoreo del medio ambiente.
Fuente: MIT News – AI





Leave a Comment